Scrum people like to use points for estimating and measuring velocity. I won’t go into detail about how points work and how to play those poker estimation games. Just search around and you will find a ton of stuff. So, back to this points stuff. I have a divided relationship with the humble point. I like it when a team switches to using points for the first time, because it gives them a chance to think a little bit deeper about what they want to do. I don’t like it when we start inventing rules around points (and you can lump guidelines and best practices into the rules pot too). When the rules appear, the thinking disappears.
In every team trying Scrum, there is bound to be a rule about points. I dare you to put up a hand and say you have none. These rules are things like “We can’t take anything over 13 points into a sprint”, “Our epics are 100 points”, “The login screen is our baseline of 3 points”, “Anything over 40 points must be broken down”. So, I double dare you 🙂
Sprint backlog shape with high shared understanding

I have different view of the humble point. A point may seem like a one dimensional thing, but it has a some facets built into it. One facet is the “amount of effort to build something”. Another facet is “amount of ignorance” and this has an inverse – “amount of shared knowledge”. Sometimes I find it useful to make a judgement based on what I don’t know as opposed to what I do know. Regardless of whether I choose to view the cup as half full or half empty, I cannot estimate effort to build something based upon what I don’t know. So, effort tends to track the amount of knowledge, not ignorance. As knowledge increases, my ignorance decreases and each point starts representing more and more of pure effort.

However, if I am in a state of complete ignorance, then it is completely impossible for me to make any judgement on effort to build. I’d be simply speculating. What I can do, though, is create a time box to explore the unknown so that I can start moving out of my state of ignorance. This is also an estimate and I am not making an excuse for non-delivery either. I need to understand some things and also show my understanding in some code. Yes, the code that I produce may not have a visible user interface or some other convenient demo-friendly stuff, but I need to carefully plan my sprint review to express my understanding.
It’s all about gaining a SHARED understanding. This understanding is body of knowledge that I have learned which I need to confirm with others. This act of confirmation can happen in several ways. I can have a conversation and explain what I understand, I can draw a blocks and lines picture, or show a spreadsheet, and so on. Regardless of the method of communication, I still use the opportunity of discovery to express my understanding in code as tests. Another powerful way of expressing my understanding is to write out a story and a few scenarios. Using BDD style grammar can be a great way of concisely expressing some things, that can be easily shared. Yes, you heard me correctly – as a developer, I write the stories and scenarios. When I am given a story and scenario by someone and asked to estimate, then I am attempting to estimate based on another person’s expression of their understanding and my assumed understanding.
In a recent discussion with Jimmy Nilsson, he said that he prefered to call scenarios “examples”. That really resonated with me. I also do a lot of discovery by example, and then gradually introduce more a more into the examples, as I get more and more confident of my knowledge.
How do I know how much I don’t know? That’s a tough question. What I do comes straight out of my TDD habits. I create a list of questions – my test list. For some questions, I will know the answer easily, some not all, and some are debatable. The more that I can answer, the better I can estimate effort. I can then turn the questions that I can answer into statements of fact. The more facts I have, the less ignorant I am.
Recently, I worked with a team that wanted to get TDD going, and the most significant change that I introduced was in backlog grooming and sprint planning. During these two ceremonies, we (as a team) threw questions madly at a requirement, regardless of whether we knew the answer or not. We then worked through the questions (as a team) to establish how much we could answer. The trend that emerged was that the original estimates where either half of the new estimate or double of the new estimate. When they where halved, it was generally because we were able to negotiate some of the unknowns (the ignorant areas) to a future sprint with the product owner. In some cases, the product owner was equally ignorant, and was reacting to the “business wants the feature” pressure. When they were doubled, it was so much more was discovered than originally assumed. At the end of the session, we always asked the meta-question “If we answer all these questions sufficiently, will we be done?”. I call this style of working “test first backlog grooming” or “test first sprint planning”.
Often I discover more things I don’t know. Annoyingly, this happens in the middle of a sprint, but if it did not happen in that phase of work, then perhaps I was not digging deep enough. When this happens, I just keep on adding them to my list of questions. These new questions are raised at any time with others on the team, the customer or with whoever can help me understand a bit more. Sometimes, it’s put on the table for negotiation to be dealt with at another time. Nevertheless, standups still seem to be a good time to put new questions on the table, for discussion later.
There are several ripple effects of thinking about points in this manner – this notion of ignorance and shared knowledge gauges.
The first is about the possible shape of your sprint backlog. If you have deep understanding, then it is likely that you will be able to decompose complex problems into simple solutions, that take less effort. The effect is that low point stories are in greater number in a sprint.

If you are highly ignorant, then the estimation points reflect that and there are more medium to high point stories in the sprint.
The second is about what you value in a story. You will find less value in the ontology of epics, themes and stories. It is no longer about size of effort but degree of understanding or ignorance. Instead, the shape of the product backlog is something that is constantly shifting from high uncertainty (big point numbers) to high certainty (low point numbers). That’s what test first backlog grooming gives you.

The third is about continuous flow that is the nature of discovery. When you work steadily at reducing your degree of ignorance, then you are steadily answering questions through answers expressed in code, and steadily discovering new questions that need answering. This process of discovery is one of taking an example based on what you know in this moment and modeling it. Then expanding that example with one or two more additional twists, and modeling that, and so it goes.
It also touches product ownership and software development. When you work in this way, then explicit estimation of effort becomes less significant. Moments that have been earmarked as important points in the life of the product become more significant. Call them milestones. These milestones are strategically and tactically defined, and become a dominant part of product ownership. Software development becomes the act of having long running conversations with the customer. Those milestones give context for the content of those conversations. Ultimately, those conversations are then expressed as a set of organised thoughts in code. If your code is not organised well, then perhaps you also don’t understand the problem or solution or both.
This is a long story for a short message. A high priority is to resolve the tension that exists in an estimation in the form of knowlege/ignorance fighting against effort. When you release that tension through shared understanding, then you can deal with the tension that exists in the act of creating those significant milestones. In my opinion, that’s the real wicked problem.
 Writing this book has been quite a journey. Being a personal experiment in user experience design in a non-interactive medium has proven to be quite a challenge. The constraints are significant from page size, typography and then to consider cognitive overload and leaps from concept to concept. Yet, at the core I am still aiming for a pairing experience. I want to create an experience that someone is working with me at the same computer and sheets of paper.
Writing this book has been quite a journey. Being a personal experiment in user experience design in a non-interactive medium has proven to be quite a challenge. The constraints are significant from page size, typography and then to consider cognitive overload and leaps from concept to concept. Yet, at the core I am still aiming for a pairing experience. I want to create an experience that someone is working with me at the same computer and sheets of paper.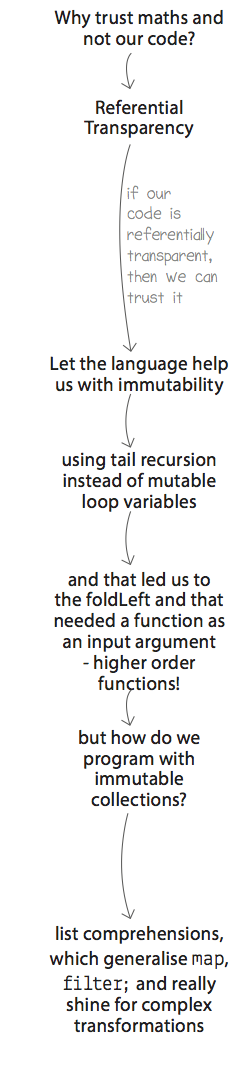 Where have I taken people on this journey so far? On the right is what I’ve covered so far. Next up are algebraic data types and then more in depth coverage of high order functions. Very surprising for me is that this journey of constraints, user experience challenges, asking super power questions has led me to shifting this chapter on high order functions from being chapter 2 to chapter 7. That was unexpected.
Where have I taken people on this journey so far? On the right is what I’ve covered so far. Next up are algebraic data types and then more in depth coverage of high order functions. Very surprising for me is that this journey of constraints, user experience challenges, asking super power questions has led me to shifting this chapter on high order functions from being chapter 2 to chapter 7. That was unexpected.



